Bob talks
Bob Stuart, creator of MQA, talks in detail about this revolutionary British technology that sets a new standard in capturing, delivering and reproducing digital audio.
Appendix 2: Test Signals and Music
How did the buried signals differ from music”?
The sounds we use in speech, music and communication share two properties with natural sounds which are: ‘self-similarity’, and ‘finite rate of innovation’. One consequence of this is that lower frequencies tend to be higher in level than higher frequencies.
We cover this topic extensively in the ‘Hierarchical paper’.[1]
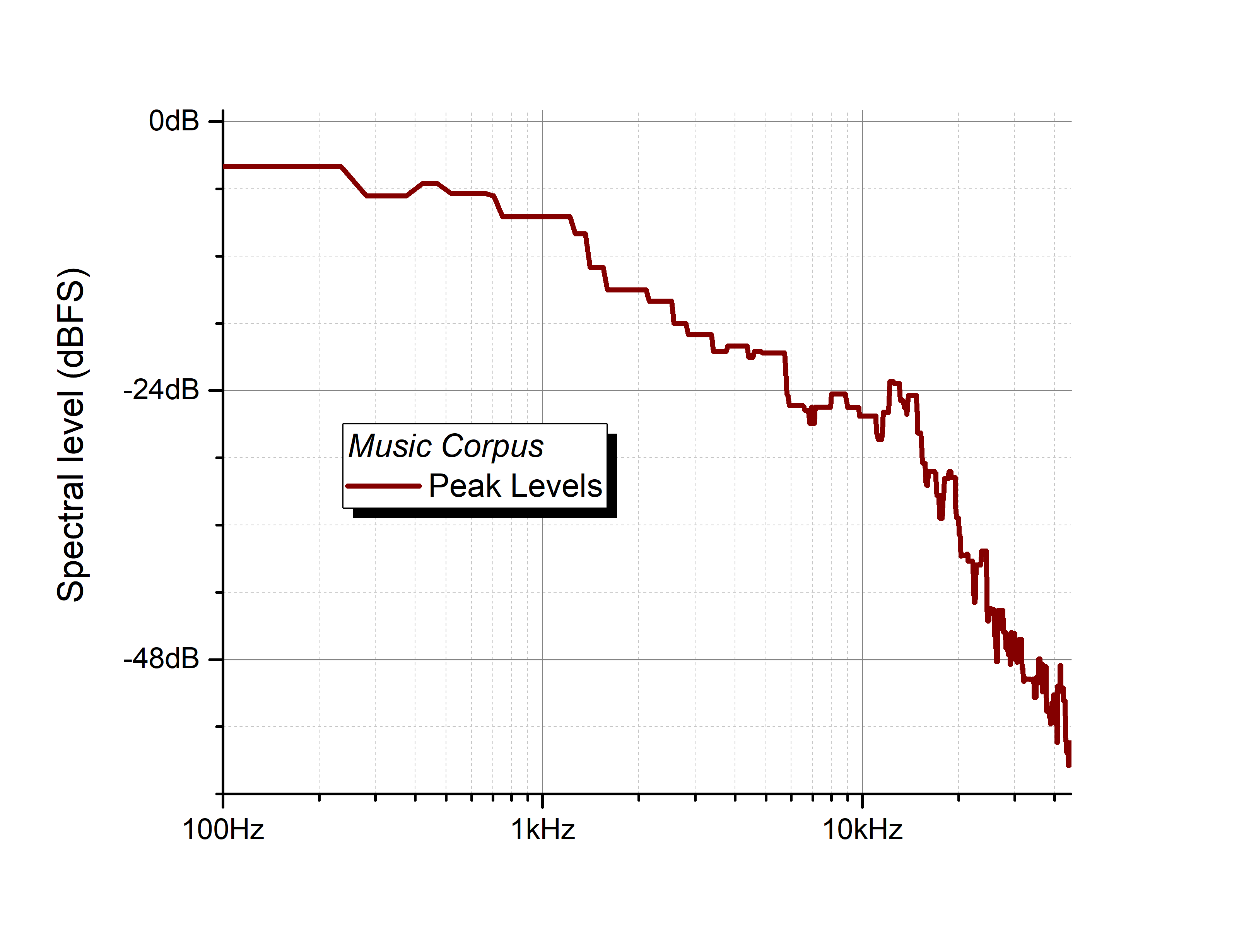 |
The graph (click for a bigger view) shows the maximum level vs frequency for a large corpus of music recorded with samples rates of 88.2 kHz and above, including techno, electronica & metal as well as rock, pop, jazz and classical. [2] In this case, frequency is plotted on a log scale, which more closely corresponds to our sense of pitch. We can see that the bulk of the energy is below 12 kHz. [3] |
This graph showed the highest level at each frequency across all songs, but each individual music recording has its own peak spectrum and a noise floor.[4]
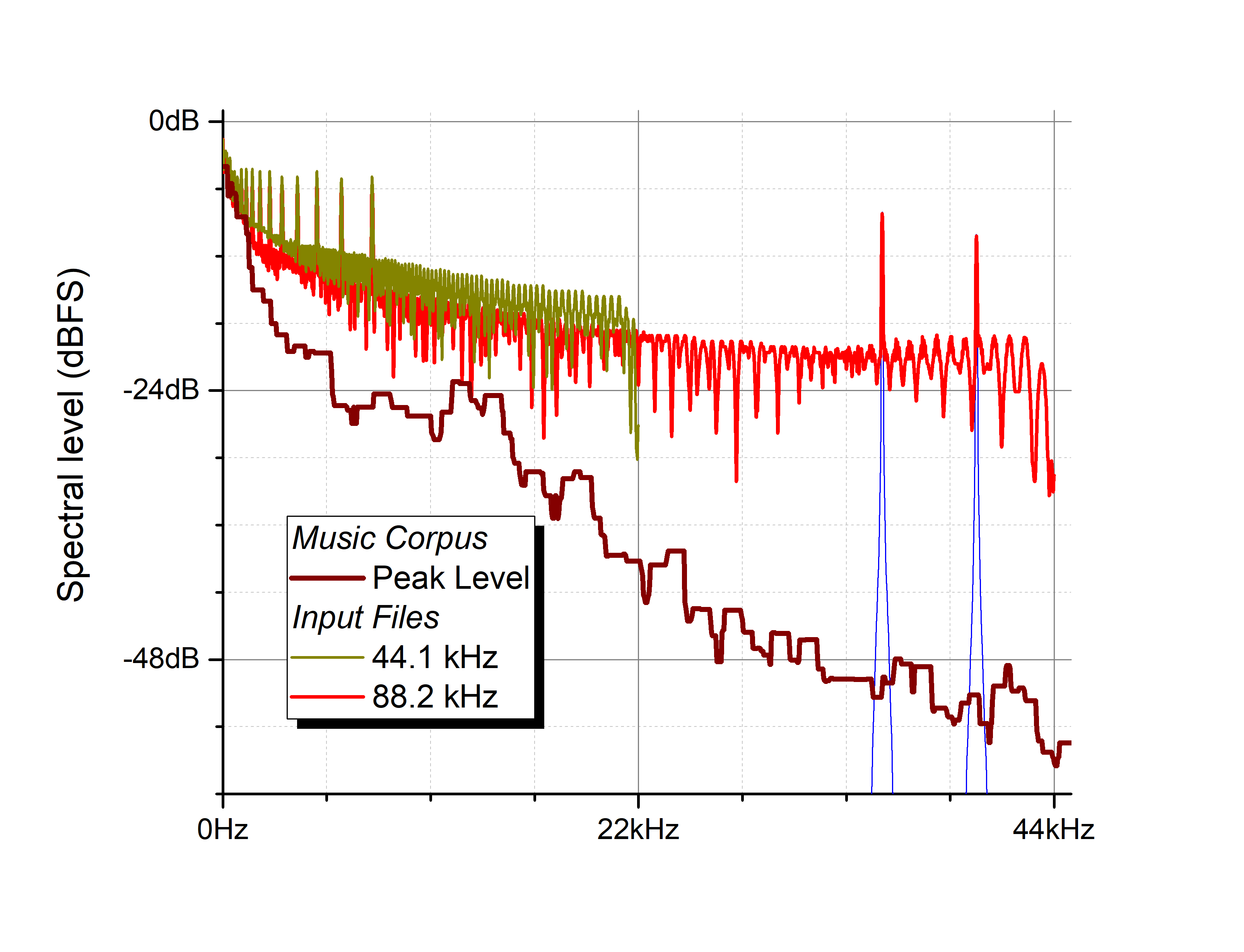 |
The graph opposite is plotted on a linear frequency scale (that corresponds to information). Brown line is the corpus peak level shown above. [5] Olive is the maximum spectrum for the 44.1 kHz test file. Red is the maximum spectrum for the 88.2 kHz test file. Blue spotlights the near-full-scale ultrasonic twin-tone. |
So, how then were these test signals different from real music? This is made clear in the diagram above.
- The 44.1 kHz composite file included very high levels that at 22 kHz exceed music content by 20 dB.
- The 88.2 kHz composite file included very high levels right up to 44 kHz.
- At 44 kHz it exceeded the music corpus by more than 30 dB.
- Worse, the ultrasonic signal exceeded known music by a factor of 100, i.e. 40 dB.
- More than half the total power of this signal is above 20 kHz and it is dangerous – such extreme ultrasonic energy would readily damage tweeters or amplifiers.
- A huge difference between music and the test file submitted is the power above 20 kHz. For example, even for an extreme ‘metal’ recording, only 1% of the average power is in the octave 22 – 44 kHz.
- Professional mastering engineers are extremely careful to avoid any high-frequency whistles or interference above 20 kHz, as seen by the brown line.
- As described earlier, neither of the submitted files had a consistent noise floor and the encoder also warned of this.
For a number of good reasons that we explain in the next Appendix, an automatic MQA encoder will struggle on this content. Indeed we deduce that the test sequences were chosen in bad faith, specifically to overload the MQA process.
Our reply to the blogger
In our reply to the blogger before he published,[6] we explained that there are different classes of MQA encoder according to application. Extensive tools and facilities are available to mastering engineers and labels. Even more facilities to control the deblurring and encapsulation processes are used for white-glove projects. A key section in our reply says this:
“To help young artists and small labels get their music encoded in MQA and on to TIDAL, we recently enabled the service you used. However, that service is limited in flexibility and places obligations on the user. First, the encoder is fully automatic, which means it will use analysis to set parameters for each song as a whole; second it is intended strictly for music. This encoder is not configured to deal with content where, for example, the statistics change mid-song, or where the audio does not resemble natural sound. The onus is on the submitter to check the content when it arrives in TIDAL and confirm the sound. In this way, we can all be sure that the provider is happy with the Master and that, because of the light, everyone with an MQA decoder is getting the intended sound.”
We also pointed out the following:
“ …. the analysis phase of the encoder objected outright to 11 of the 14 files you submitted. The three that passed through had these warnings in the log returns which should have caused the user to check:
“Audio invalid – Excessive alias …”
“Audio invalid – Input audio is predominantly 16 bits while file container is 24 bits”
“Input audio appears to have been wrapped”,
“Input audio contains a band edge …”
“Encode may not have worked as desired and may require further QC”
So, there is a requirement that the file be of music, an onus on the submitter to heed system warnings and then to check the content on TIDAL. In this case, none of these conditions were met. Further, having been reminded by us in good time of the errors, the blog was posted anyway! That was an extraordinary thing to do.
No investigator of integrity would publish results based on known-flawed experiments.
The result was not a well-conducted experiment and revealed nothing of any significance beyond a predisposed bias, amateurism, lack of rigour, bad faith – ‘Garbage in, garbage out’.
Next: Appendix 3: The Musical Triangle
Footnotes
[1] Stuart, J. Robert; Craven, Peter G., ‘A Hierarchical Approach for Audio Archive and Distribution’, JAES Volume 67 Issue 5 pp. 258-277; May 2019. Open Access http://www.aes.org/e-lib/browse.cfm?elib=20456
[2] The MQA encoder has gathered statistics for the millions of songs encoded so far in all genres. This gives us good confidence when we show pictures regarding peak levels and noise-floor.
[3] This is why tweeters do not need to handle the same power as a mid-range driver.
[4] Noise floor analysis of recorded music was analysed and shown in: Stuart, J. Robert; Craven, Peter G., ‘A Hierarchical Approach for Audio Archive and Distribution’, JAES Volume 67 Issue 5 pp. 258-277; May 2019. Open Access http://www.aes.org/e-lib/browse.cfm?elib=20456
[5] Basically, real music does not exceed this spectrum.
[6] Our complete response can be found here https://bit.ly/3e3yYF3
Index
All that glitters is not gold(en)
Appendix 1: A ‘Tarnished Test Signal’
Appendix 2: Test Signals and Music
Appendix 3: The Musical Triangle